ToMe
Paper: TOKEN MERGING: YOUR VIT BUT FASTER
Code: ToMe
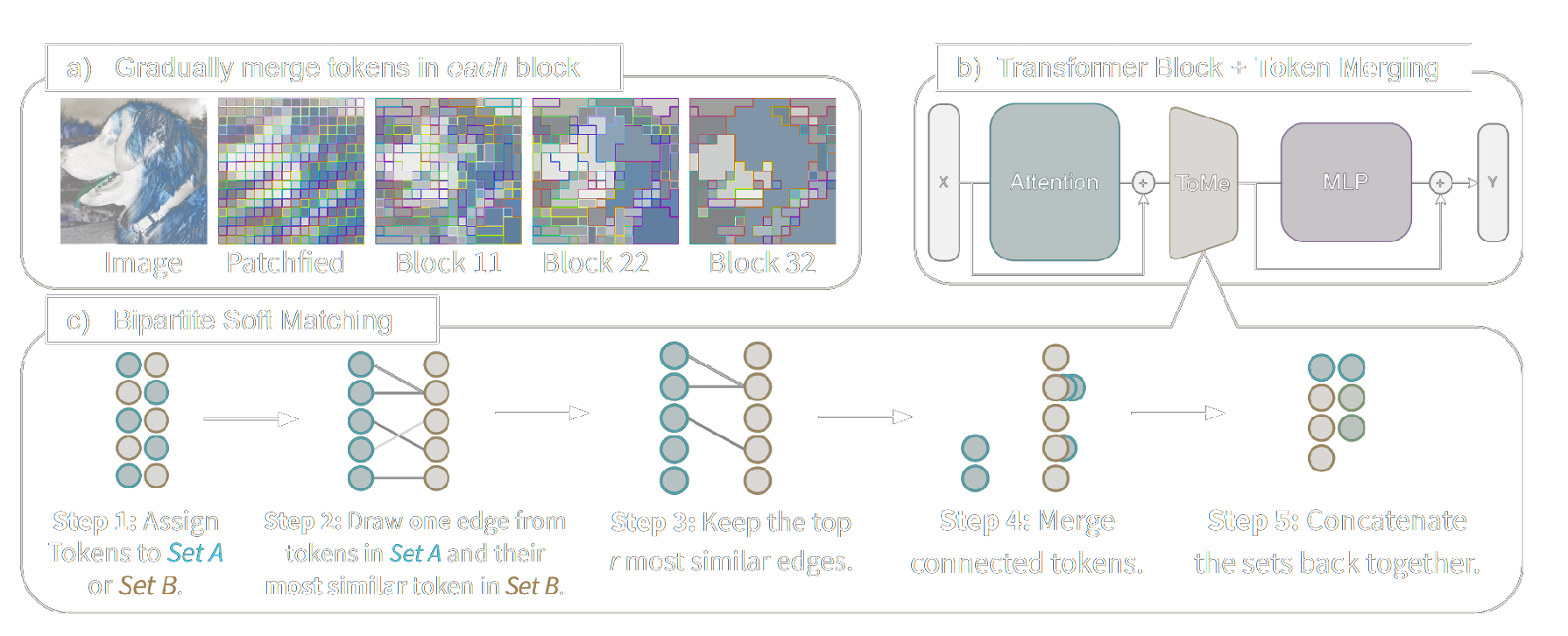
Overview
ToMe's attension:
B, N, C = x.shape
qkv = (
self.qkv(x)
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
.permute(2, 0, 3, 1, 4)
)
q, k, v = (qkv[0], qkv[1], qkv[2])
attn = (q @ k.transpose(-2, -1)) * self.scale
# Apply proportional attention (Size is the number of tokens merged into each token, used for proportional attention)
if size is not None:
attn = attn + size.log()[:, None, None, :, 0]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
# Metric is simply the mean (over multiple heads) between tokens's key.
metrics = k.mean(1)
ToMe use mean over multiple heads, similar to EViT and Top-K. Proportional attention need to be handled specially, which is not used in EViT and Top-K.
metric = metric / metric.norm(dim=-1, keepdim=True)
a, b = metric[..., ::2, :], metric[..., 1::2, :]
# Here scoring attention is computed using key from the original tokens, which is different from EViT and Top-K.
scores = a @ b.transpose(-1, -2)
if class_token:
scores[..., 0, :] = -math.inf
if distill_token:
scores[..., :, 0] = -math.inf
# For each node in `a`, find the node in `b` with the highest similarity score.
node_max, node_idx = scores.max(dim=-1)
# Sort the nodes in `a` based on their maximum similarity score to nodes in `b`.
edge_idx = node_max.argsort(dim=-1, descending=True)[..., None]
# Select the top `r` nodes in `a` to merge.
unm_idx = edge_idx[..., r:, :] # Unmerged Tokens
src_idx = edge_idx[..., :r, :] # Merged Tokens
# For each node in `a`, find the node in `b` that it is merged to.
dst_idx = node_idx[..., None].gather(dim=-2, index=src_idx)
def merge(x: torch.Tensor, mode="mean") -> torch.Tensor:
src, dst = x[..., ::2, :], x[..., 1::2, :]
n, t1, c = src.shape
# Merge the tokens in `src` to the corresponding tokens in `dst` based on `dst_idx`.
unm = src.gather(dim=-2, index=unm_idx.expand(n, t1 - r, c))
src = src.gather(dim=-2, index=src_idx.expand(n, r, c))
dst = dst.scatter_reduce(-2, dst_idx.expand(n, r, c), src, reduce=mode)
# Weighted average of the merged tokens, also update the size of the merged tokens
x = merge(x * size, mode="sum")
size = merge(size, mode="sum")